Extracting data from Domino into PDF using XSLT and XSL:FO (Part 1)

This entry is part of the series Domino, XSL:FO and XSLT that dives into the use of XSLT and XSL:FO in IBM Lotus Domino.
We all know " Notes doesn't print". Nevertheless the topic of document output and reports is not going away, even if I'd like to ban the reports. There are plenty of ready made tools, but today I'd like to start with home cooked reporting.
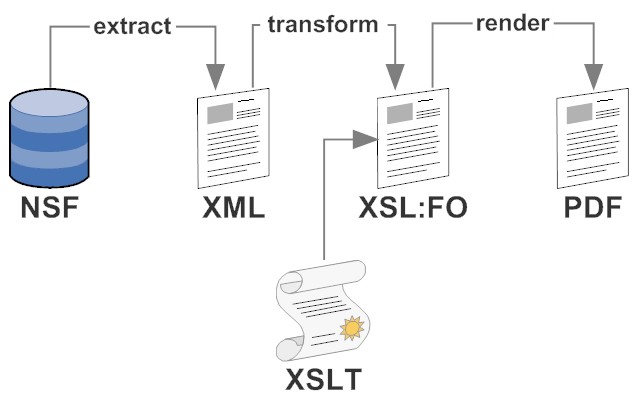
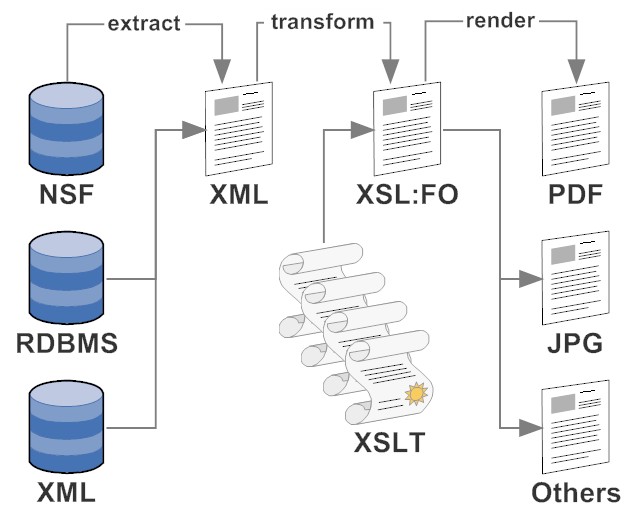
Why the effort? Using only tools that use open standards you gain more control over the whole process and you can use whatever deems fit. The downside: it is more things you need to know and might not be suitable for business users (but its great to torture interns). In the long run you have a portfolio of source transformations that you can combine potentially faster than any reporting tool. The general principle is "Extract Transform Render":
Now the stage is set for more details - in future post. I will look at the code that is needed to have a render engine running (in XPages most likely, but the Notes client is tempting too), how XSL:FO looks like, some samples of data extraction and of course the magic of XSLT.
Read Part 2 and stay tuned!
We all know " Notes doesn't print". Nevertheless the topic of document output and reports is not going away, even if I'd like to ban the reports. There are plenty of ready made tools, but today I'd like to start with home cooked reporting.
Why the effort? Using only tools that use open standards you gain more control over the whole process and you can use whatever deems fit. The downside: it is more things you need to know and might not be suitable for business users (but its great to torture interns). In the long run you have a portfolio of source transformations that you can combine potentially faster than any reporting tool. The general principle is "Extract Transform Render":
- Extract:
Whatever will pull out the XML for the second step will do the trick. For list type of rendering?ReadViewEntrieswill do the trick or simple DXL exports. Quite often you might opt for some bespoke code to extract code with an eye of a fast and/or easy transformation phase. You also might consider to extract your data in conformance with an established international standard - Transform:
This step usually takes the XML from the extract phase and runs it through one or more XSLT transformations. XSLT is kind of IT Black Magic(other say it's just set theory) and can use quite some computing power. For high performance the pros use a dedicated applicance. Once you get the heck of XPath you can do some amazing reporting (e.g. "give me all sales guys where withing the last 5 sales of the 3 guys next to his ranking there was a carpenter")
- Render:
Rendering is easy. The outcome of the transformation step will be XSL:FO which is a page description language. Use a free renderer or a commercial offering and a few lines of code. The output typically is a PDF file, but you can target graphic formats too.
Now the stage is set for more details - in future post. I will look at the code that is needed to have a render engine running (in XPages most likely, but the Notes client is tempting too), how XSL:FO looks like, some samples of data extraction and of course the magic of XSLT.
Read Part 2 and stay tuned!
Posted by Stephan H Wissel on 23 April 2012 | Comments (3) | categories: Show-N-Tell Thursday XML XPages

{kind=link}