Public Tenders for complex (IT) projects - a cure worse than the disease?
Most public sector institutions require contracts higher than a certain value to be awarded by tender. In Singapore the threshold is currently SGD 70k (that's at today's exchange rate approximately USD 57K or EUR 40k). The tender process is intended to ensure an impartial award of the project at hand to the most (or sufficient) capable bidder at the lowest price. This does not only make Alan Shepard nervous (he coined the famous sentence: " The fact that every part of this ship was built by the low bidder"). Tenders work well when the defined need published in one of them is easy to fulfil and fulfilment offers are easy to compare.
However the very moment complexity kicks in a tender process gets expensive. The Australian process defines eight distinct stages a tender process goes thru until awarded. This has a number of consequences:
However the very moment complexity kicks in a tender process gets expensive. The Australian process defines eight distinct stages a tender process goes thru until awarded. This has a number of consequences:
- No small innovative company can put up with the process, so innovation stays outside
- Since the need needs to be defined tenders tend (pun intended) to cement waterfall approaches to software projects
- Tender language needs to be vender neutral, so it is fun to see how tender documents try to disguise vendor specific features in neutral language or broad requirements no one can deliver (e.g. "messaging platform needs to run on all prevalent server operating systems (this kicks Exchange out) and support calendaring and scheduling for all prevalent desktop applications (this kicks basically ALL out since Calendar interoperability is all but a pipe dream)".
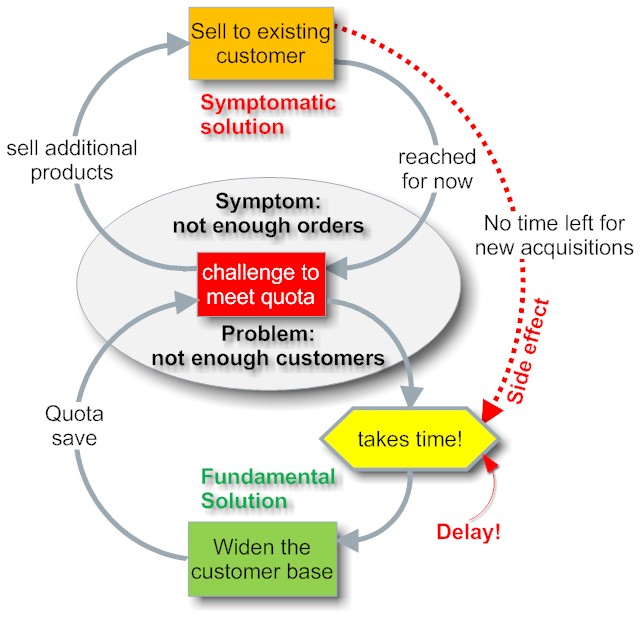
- Since large tenders are attended only by a selected few, the public sector agencies will be overcharged. This is not malice on the side of the tender submitters, but simple economic logic. Let us look at a simplified example: In a small country, let us call it Morovia
there are 5 system integrators (SI) that are eligible to bid for contracts for 1M and more. Due to the competitive pressure all of them bid for all of the projects. Since Morovia is looking into the future software projects are large and complex and end up with 1M budget each.
All SI spend about 10% of each tender's value on running it through all the phases up to the final award, which as the nature of the tender process stipulates, goes to one only (I prepared a lot tenders and can assure you, that a lot of SI would be happy with 10%).
All SI are highly qualified, so they win an average 1 out of 5 tenders. So far so good. But once you run the numbers (after all they are in business, striving for profit) you realise, that they had to spend 500k acquisition cost for 1M of contract value, leaving only 500k value to be delivered in the project. 50c on 1$ isn't a very desirable outcome. I wonder what other projects are plagued by under-funding too
Posted by Stephan H Wissel on 30 May 2011 | Comments (1) | categories: Business
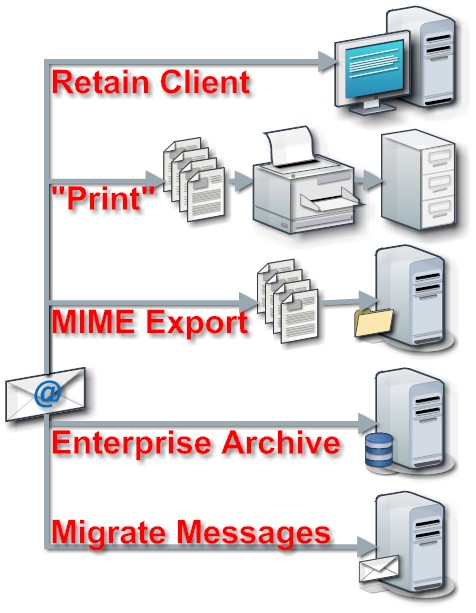 Setting up an eMail server or signing up for a
Setting up an eMail server or signing up for a 



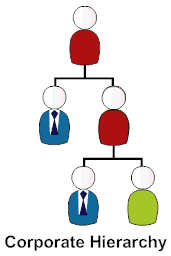 The trickiest problem in KM and to a large extend in eLearning is the classification of items. Taking a hint from classical science the first approach was to use a
The trickiest problem in KM and to a large extend in eLearning is the classification of items. Taking a hint from classical science the first approach was to use a 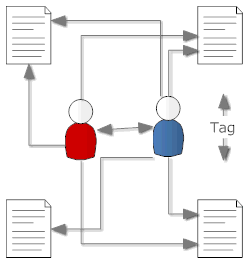 The rise of social computing with sites like
The rise of social computing with sites like 

{kind=link}