The 3 P of Performance: Passion, Professionalism and Persistence
Every corporation celebrates their heroes (and enlightened ones mourn their losses too). I've been made Hero of the day in the quarterly GMU Breakaway Star recognition for the inaugural Q2/2011 (GMU is IBM's TLA for "Growth Market Unit", which means: the world excluding US, Europe and Japan: Dear Stephan
Congratulations on your recent selection as one of the GMU Breakaway Stars in recognition of your outstanding contribution to our Software business in 2Q!
The GMU Breakaway Stars program recognizes high performers who have achieved extraordinary results for the business and have demonstrated their understanding of the client's business, their ability to integrate IBM in front of the clients and their passion to drive progress for clients, for IBM, and for themselves.
As a GMU Breakaway Star, you have exemplified the quality of IBMers at their best. I am pleased to see your commitment to excellence and IBM values; and your dedication to create differentiation and higher value for our clients. This is the quality which will differentiate IBM in the marketplace and position us to achieve our 2015 roadmap.
As we continue to deliver growth for the business, I hope you will contribute the same level of focus and commitment that you displayed to help position us as the 'Best Partner of Choice' for our clients.
Thank you once again for your exceptional achievements in 2Q. Keep up the great work!"
I got featured on the IBM Intranet (which I can't share) and interviewed. I would title that interview: "The 3 P of Performance: Passion, Professionalism and Persistence"
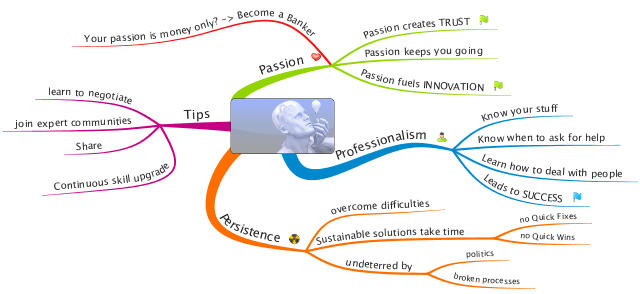
The little flags on the right side together with the words in caps point to IBM's core values: Success, Innovation and Trust. It is always fun and rewarding to tie actions back to the stated core values, they are everywhere in danger to bet let out of sight in the heat of the battle.
Carrot accepted, now back to the stick of quarterly numbers.
Congratulations on your recent selection as one of the GMU Breakaway Stars in recognition of your outstanding contribution to our Software business in 2Q!
The GMU Breakaway Stars program recognizes high performers who have achieved extraordinary results for the business and have demonstrated their understanding of the client's business, their ability to integrate IBM in front of the clients and their passion to drive progress for clients, for IBM, and for themselves.
As a GMU Breakaway Star, you have exemplified the quality of IBMers at their best. I am pleased to see your commitment to excellence and IBM values; and your dedication to create differentiation and higher value for our clients. This is the quality which will differentiate IBM in the marketplace and position us to achieve our 2015 roadmap.
As we continue to deliver growth for the business, I hope you will contribute the same level of focus and commitment that you displayed to help position us as the 'Best Partner of Choice' for our clients.
Thank you once again for your exceptional achievements in 2Q. Keep up the great work!"
I got featured on the IBM Intranet (which I can't share) and interviewed. I would title that interview: "The 3 P of Performance: Passion, Professionalism and Persistence"
The little flags on the right side together with the words in caps point to IBM's core values: Success, Innovation and Trust. It is always fun and rewarding to tie actions back to the stated core values, they are everywhere in danger to bet let out of sight in the heat of the battle.
Carrot accepted, now back to the stick of quarterly numbers.
Posted by Stephan H Wissel on 29 September 2011 | Comments (7) | categories: IBM
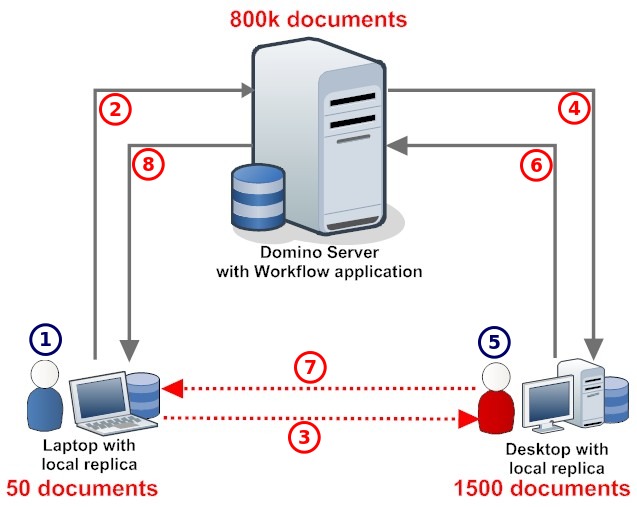
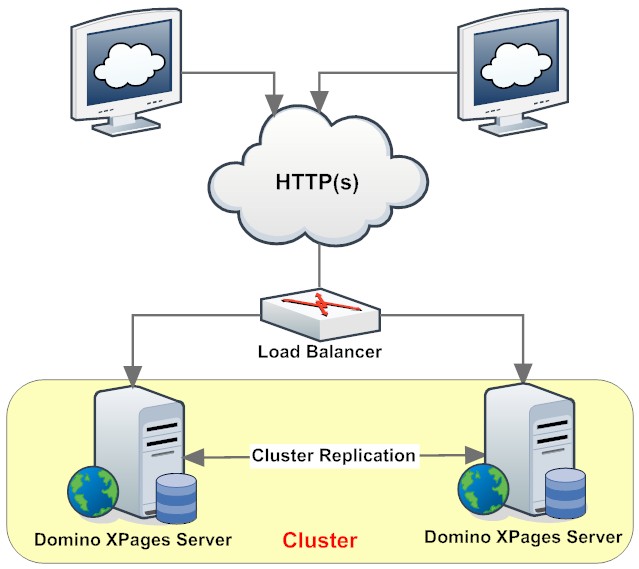
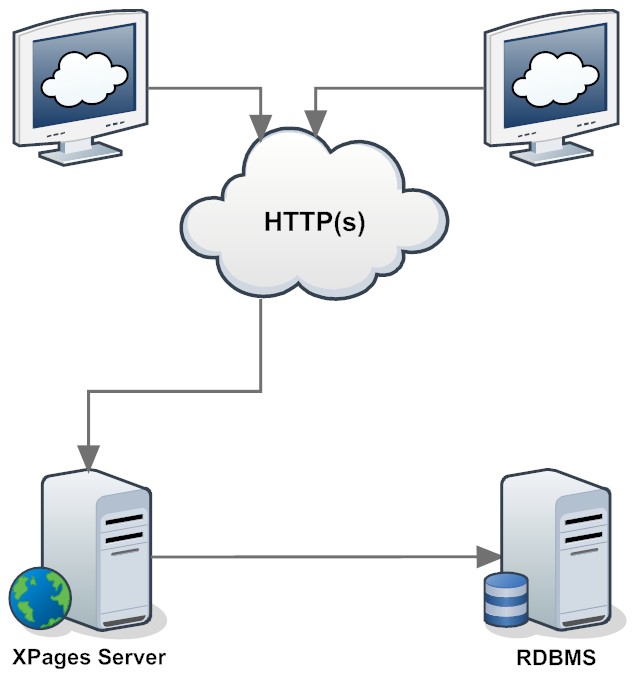
 . Getting the gist of a platform often requires a zen like approach. Unfortunately in the heat of delivery pressures things get lost and we end up with "Frankenworks" instead of "Frameworks", where functionality works, but feels rather "bolted on".
. Getting the gist of a platform often requires a zen like approach. Unfortunately in the heat of delivery pressures things get lost and we end up with "Frankenworks" instead of "Frameworks", where functionality works, but feels rather "bolted on".
{kind=link}